The Windows Performance Monitor tool is part of a larger suite of data collection tools called the Reliability and Performance Monitor. Performance Monitor collects detailed information about the utilization of operating system resources. It allows you to track nearly every aspect of system performance, including memory, disk, processor, and network.
Performance Monitor tracks resource behavior by capturing performance data generated by hardware and software components of the system such as a processor, a process, a thread, and so on. The performance data generated by a system component is represented by a performance object.
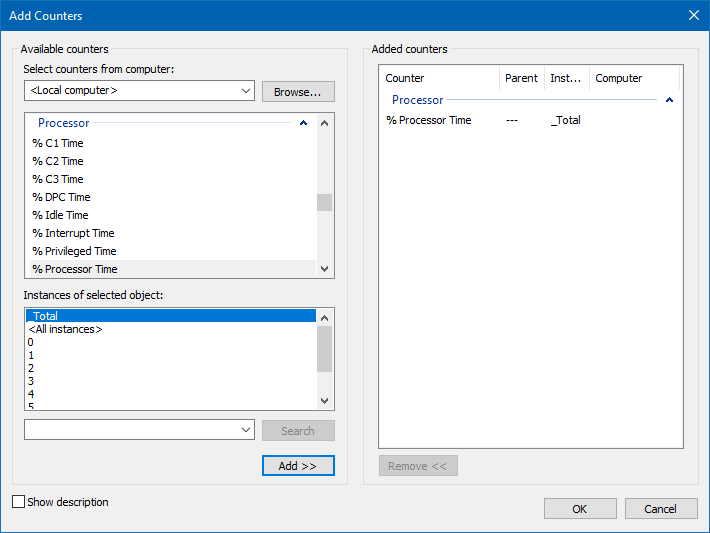
There can be multiple instances of a system component. For instance, the processor object in a compute with two processors will have two instances represented as instances 0 and 1. performance objects with multiple instances may also have an instance called _Total to represent the total value for all the instances.
To run the Performance Monitor tool, execute Perfmon from a command prompt, which will open the Reliability and Performance Monitor suite.
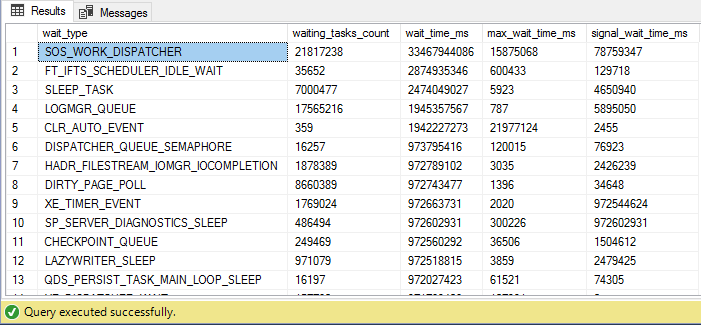 SELECT * FROM sys.dm_os_wait_stats ORDER BY wait_time_ms DESC
SELECT * FROM sys.dm_os_wait_stats ORDER BY wait_time_ms DESC
To get an immediate snapshot of a large amount of data that was formerly available only in Performance Monitor, SQL Server now offers the same data internally through a set of dynamic management views (DMVs) and dynamic management functions (DMFs). These are extremely useful mechanisms for capturing a snapshot of the current performance of your system.
There are a large number of DMVs and DMFs that can be used to gather information about the server. Sys.dm_os_wait_stats show an aggregated view of the threads within SQL Server that are waiting on various resources, collected since the last time SQL Server was started or the counters were reset. Identifying the types of waits that are occurring within your system is one of the easiest mechanisms to begin identifying the source of your bottlenecks.
Hardware Resource Bottlenecks
Typically, SQL Server database performance is affected by stress on the following hardware resources:
- Memory
- Disk I/O
- Processor
- Network
Stress beyond the capacity of a hardware resource forms a bottleneck. To address the overall performance of a system, you need to identify these bottlenecks, because they form the limit on overall system performance.
Bottleneck Resolution
Increasing the throughput usually requires extra resources such as memory, disks, processors, or network adapters. You can decrease the arrival rate by being more selective about the requests to a resource. For example, when you have a disk subsystem bottleneck, you can either increase the throughput of the disk subsystem or decrease the number of I/O requests.
Increasing the throughput means adding more disks or upgrading to faster disks, decreasing the arrival rate means identifying the cause of high I/O requests to the disk subsystem and applying resolutions to decrease their number.
Memory Bottleneck Analysis (Performance Counters)
Memory can be a problematic bottleneck because a memory bottleneck will manifest in other resources too. This is particularly true for a system running SQL Server.
Processor
- When the SQL Server goes out of cache, the Lazywriter process swap in some part of the memory to the disk.
- To provide enough cache space for SQL Server, which this process extremely increases the CPU cycles.
Disk I/O
When the CPU Cycle is extremely increased, The Disk I/O operations will be increased because of moving the pages from Memory to Disk and From Disk to Memory.
-
Available Bytes: The Available Bytes counter represents free physical memory in the system. For good performance, the value should not be too low.
-
Pages/Sec and Page Faults/Sec: A page fault occurs when a process requires code or data that is not in its working set. It may lead to a soft page fault or a hard page fault. If the faulted page is found elsewhere in physical memory, then it is called a soft page fault. A hard page fault occurs when a process requires code or data that is not in its working set or elsewhere in physical memory and must be retrieved from the disk. For example, the SQL Server process is represented by the SQL Server instance of the Process object. High numbers for Page Faults/Sec usually do not mean much unless Pages/Sec is high. The Pages/Sec counter represents the number of pages read from or written to disk per second to resolve hard page faults. The Page Faults/Sec counter indicates the total page faults per second handled by the system. Hard page faults, indicated by Pages/Sec, should not be consistently high. If this counter is consistently very high, then SQL Server is probably starving other applications. There are no hard and fast numbers for what indicates a problem due to system differences. Pages Input/Sec indicates that an application will wait only on an input page, not on an output page. Pages Output/Sec indicate that system is stressed, but an application usually does not see this stress. Pages output is usually represented by the application’s dirty pages that need to be backed out to the disk.
-
Buffer Cache Hit Ratio: The counter value should be as high as possible, especially for an OLTP system that should have fairly regimented data access. A low value indicates that few requests could be served out of the buffer cache, with the rest of the requests being served from the disk. If this is consistently low, you should consider getting more memory for the system.
-
Page Life Expectancy: This counter indicates how long a page will stay in the buffer pool without being referenced. A low number for this counter means the possibility of memory pressure. The reasonable value to expect to see is 300 seconds or more.
-
Checkpoint Pages/Sec: This counter indicates the number of pages that are moved to disk by a checkpoint operation. These numbers should be relatively low. Higher values on this counter indicate a larger number of writes occurring within the system, possibly indicative of I/O problems.
-
Lazy Writers/Sec: This counter records the number of buffers written each second b the buffer manager’s lazy write process. This process is where the dirty, aged buffers are removed from the buffer by a system process that frees the memory up for other uses. The counter value should consistently be less than 20 for the average systems.
-
Memory Grants Pending: This counter represents the number of processes pending for a memory grant within SQL Server memory. If the value is high, then SQL Server is short of memory. The number should be constantly 0 in normal conditions.
-
Target Server Memory (KB): This counter indicates the total amount of dynamic memory SQL Server is willing to consume.
-
Total Server Memory (KB): This counter indicates the amount of memory currently assigned to the SQL Server. This counter value can be very high if the system is dedicated to SQL Server.
-
Private Bytes: This counter indicates the amount of space that has been allocated in the swap file to hold the contents of the private memory if it is swapped out.
Memory Bottleneck Resolution
-
Optimizing Application Workload: Optimizing application workload is the most effective resolution most of the time, but because of the complexity and challenges involved in this process, it is usually considered a last resort.
-
Allocating More Memory to SQL Server: If the memory requirement of SQL Server is more than the max server memory value, which you can tell through the number of hard page faults, then increasing the value will allow the memory pool to grow. To benefit from increasing the max server memory value, ensure that enough physical memory is available in the system.
-
Increasing System Memory: The memory requirement of SQL Server depends on the total amount of data processed by SQL activities. It is not directly correlated to the size of the database or the number of incoming queries. Something to keep in mind is the memory needed by SQL Server outside the buffer pool. This is referred to as Non-Buffer Memory and used to be called MemToLeave.
-
Changing from 32-bit to a 64-bit Processor: Switching the physical server from a 32-bit processor to a 64-bit processor radically changes the memory management capabilities of SQL Server. The limitations on SQL Server for memory go from 3GB to a limit of up to 8TB (Prior SQL Server 2016) or 128TB (SQL Server 2016) depending on the version of the operating system and the specific processor type.
-
Enabling 3GB of Process Space: On a machine with 4GB of physical memory and the default Windows configuration, you will find available memory of about 2GB or more. To let SQ Server use up to 3GB of the available memory, you can enable the /3GB switch in boot.ini.
-
Using Memory Beyond 4GB Within SQL Server: Accessing memory beyond 4GB in a 32-bit Windows Server OS requires configuration at two levels, the operating system level, and the SQL Server level. To enable the operating system to access more than 4GB of physical memory, add a /PAE switch in the boot.ini file. Once /PAE switch is enabled, you can enable Address Windowing Extension (AWE) in SQL Server.
Memory Capacity Planning
It is quite challenging to determine how much memory will be used by SQL Server, therefore infrastructure team needs to provide sufficient physical memory to the server. most of the time insufficient memory capacity can cause CPU and I/O bottlenecks if the databases are not tuned well.
Windows Server
Windows Server is one of the major memory consumers in production servers, to estimate how much memory it consumes highly depends on processor architecture and the mode of operation either with GUI or CORE. The following formulas guide you, on how to estimate memory consumption.
Note: Only applicable on Windows Server 2008 and later versions.
For X86 Architecture – GUI
Physical Memory <= 16GB, then 10%
Physical Memory >16GB and <=64GB, then 10% from 16GB and 5% from the extra.
Physical Memory >64GB, then 10% from 16GB, 5% from 48GB and 2.5% from the extra.
For X86 Architecture – CORE
Physical Memory <= 16GB, then 10%
Physical Memory >16GB and <=64GB, then 10% from 16GB and 2.5% from the extra.
Physical Memory >64GB, then 10% from 16GB, 2.5% from 48GB and 1.5% from the extra.
For X64 Architecture – GUI
Physical Memory <= 16GB, then 25%
Physical Memory >16GB and <=64GB, then 25% from 16GB and 10% from the extra.
Physical Memory >64GB, then 25% from 16GB, 10% from 48GB and 5% from the extra.
For X64 Architecture – CORE
Physical Memory <= 16GB, then 20%
Physical Memory >16GB and <=64GB, then 20% from 16GB and 7.5% from the extra.
Physical Memory >64GB, then 20% from 16GB, 7.5% from 48GB and 2.5% from the extra.
For IA64 Architecture – GUI
Physical Memory <= 16GB, then 25%
Physical Memory >16GB and <=64GB, then 25% from 16GB and 15% from the extra.
Physical Memory >64GB, then 25% from 16GB, 15% from 48GB and 7.5% from the extra.
For IA64 Architecture – CORE
Physical Memory <= 16GB, then 20%
Physical Memory >16GB and <=64GB, then 20% from 16GB and 10% from the extra.
Physical Memory >64GB, then 20% from 16GB, 10% from 48GB and 5% from the extra.
SQL Server Dynamic Link Libraries (DLLs)
SQL Server loads many DLLs to provide full functionalities, therefore the hardware should have sufficient memory capacity to load them.
For x86 Architecture: 750MB
For x64 Architecture: 1000MB
For IA64 Architecture: 1200MB
SQL Server Memory-To-Leave (MTL)
MTL is the memory section of SQL Server for worker threads, backup operations, locks, etc. This part of SQL Server memory is very important and should have sufficient space, otherwise, SQL Server steals memory from the Buffer Pool section to accomplish mentioned operations, which causes overall performance degrading.
For X86 Architecture
MTL = #Schedulers x 255 x 0.512MB
For X64 Architecture
MTL = #Schedulers x 255 x 2MB
For IA64 Architecture
MTL = #Schedulers x 255 x 4MB
SQL Server Plan Cache
SQL Server creates plan cache objects for better performance (I would not go into detail). Plan cache has its memory section, this memory section is critical and should have sufficient capacity to avoid Local or Global Memory Pressure. You may refer to the SQL Server Memory Pressure blog post for more information. Plan Cache memory consumption formula differs from one version to the next version.
For SQL Server 2005 RTM and Service Pack 1
Physical Memory <= 8GB, then 75%
Physical Memory > 8GB and <= 64GB, then 75% from 8GB and 50% from extra.
Physical Memory > 64GB, then 75% from 8GB, 50% from 48GB and 25% from extra.
For SQL Server 2005 Service Pack 2 and Later (Up to SQL Server 2016)
Physical Memory <= 4GB, then 75%
Physical Memory > 4GB and <= 64GB, then 75% from 4GB and 10% from extra.
Physical Memory > 64GB, then 75% from 4GB, 10% from 48GB and 5% from extra.
SQL Server Buffer Pool
Buffer Pool is the memory section that keeps all data pages and needs to have sufficient memory capacity to keep data on memory as long as possible. insufficient space can cause disk I/O bottleneck due to Swap In/Out data pages. Estimating Buffer Pool size is differed by the system, we will take a look at OLTP and OLAP systems.
For Transactional System – OLTP
Buffer Pool = 1/6 of the Active portion of the database or the 1/10 of entire database size (excluding empty data pages)
For Analytical Systems – OLAP (Data Warehouse)
Buffer Pool = 20% – 30% of the total database size.
Disk Bottleneck Analysis
SQL server is a heavy user of the hard disk, and since disk speeds are comparatively much slower than memory and processor speeds, a contention in disk resources can significantly degrade SQL Server performance. Analysis and resolution of any disk resource bottleneck can improve SQL Server performance significantly.
The Physical Disk counters represent the activity on a physical disk. Note that for a hardware RAID subsystem, the counters treat the array as a single physical disk.
-
% Disk Time: This counter monitors the percentage of time the disk is busy with read/write activities. It should not be continuously high. If this counter value is consistently more than 85 percent, then you must take steps to bring it down.
-
Current Disk Queue Length: This counter is the number of requests outstanding on the disk subsystem at the time the performance data is collected. It includes requests in service at the time of the snapshot. A consistent disk queue length of two per disk indicates the possibility of a bottleneck on the disk.
-
Avg. Disk Queue Length: This counter represents the average of the instantaneous values provided by the Current Disk Queue Length counter.
-
Disk Transfers/Sec: This counter monitors the rate of read and write operations on the disk. A typical disk today can do about 180 disk transfers per second for sequential I/O and 100 disk transfers per second for random I/O.
-
Avg. Disk Sec/Read: This counter tracks the average amount of time it takes in milliseconds to read from a disk. If it’s taking more than about 10ms to move data from the disk, you may need to take a look at the hardware and configuration to be sure everything is working correctly.
-
Avg. Disk Sec/Write: This counter tracks the average amount of time it takes in milliseconds to write to a disk. If it’s taking more than about 10ms to move data to disk, you may need to take a look at the hardware and configuration to be sure everything is working correctly.
-
Disk Bytes/Sec: This counter monitors the rate at which bytes are transferred to or from the disk during read or write operations. A typical disk can transfer about 10MB per second. OLTP applications are not constrained by the disk transfer capacity of the disk subsystem since they access small amounts of data in each database request.
Disk Bottleneck Resolution
Optimizing application workload is the most effective resolution most of the time, but because of the complexity and challenges involved in this process, it is usually considered as last resort.
-
Using a Faster Disk Drive: One of the easiest resolutions, and one that you will adopt most of the time, however you should not just upgrade disk drives without further investigations.
-
Using a RAID Array: One way of obtaining disk I/O parallelism is to create a single pool of drives to serve all SQL Server database files, excluding Transaction Log files. The effectiveness of a drive pool depends on the configuration of the RAID disks. The most commonly used RAID are the following:
- RAID 0: Striping with no fault tolerance
- RAID 1: Mirroring
- RAID 5: Striping with parity
- RAID 1+0: Striping with Mirroring
-
Using a SAN System: SAN remain largely the domain of large-scale enterprise systems. A SAN can be used to increase performance of a storage subsystem by simply providing more spindles and disk drives to read from and write to.
-
Aligning Disks Properly: The way data is stored on a disk is in a series of sectors that are stored on tracks. A disk is out of alignment when the size of the track, determined by the vendor, consists of a number of sectors different from the default size that you are writing to. That simply means a sector will be written correctly, but the next one will have to cross two tracks. This can more than double the amount of I/O required to write or red from the disk.
-
Using a Battery-Backed Controller Cache: For best performance, use a caching RAID controller for SQL Server files, because the controller guarantees that data entrusted to it is written to disk eventually, no matter how large the queue is or even if the power fails.
-
Adding System Memory: The less memory the system has, the more disk subsystem is used. When physical memory is scarce, the system starts writing the contents of memory back to disk and reading smaller blocks of data more frequently.
-
Creating Multiple Files and Filegroups: The data files belonging to a database can be grouped together in one or more filegroups for administrative and data allocation/placement purposes. In a system with multiple processors, SQL Server can take advantage of multiple files and filegroups by performing multiple parallel scans on the data file.
-
Placing the Table and Index on Separate Disks: If a system has multiple processors, SQL Server can take advantage of multiple filegroups by accessing tables and corresponding non-clustered indexes using separate I/O paths.
-
Saving Log files on Different Physical Disk: SQL Server log files should always, where possible, be located on a separate hard disk drive from all other database files. Transaction Log activity primarily consists of sequential write I/O, unlike the Random I/O required for the data files.
-
Using Partitioned Tables: In addition to simply adding files to filegroups and letting SQL Server distribute the data between them, it is possible to define a horizontal segmentation of data called a partition so that data is divided up between multiple files by the partition.
Processor Bottleneck Analysis
SQL Server is not heavy use of any available processors, unless recompilation occurs massively. Generally the processor clock cycle significantly affects on performance as computational operations such as COUNT, SUM, AVG, and some mathematical built-in functions are highly depends on processor. SQL Server can be bound to certain processor for I/O and/or Computation. Processor bottleneck can be caused by other system resource’s bottleneck such as memory.
- % Processor Time: This counter value should not be consistently high, greater than 40 percent. If the value is constantly high, your first priority is to reduce the stress on processor.
-
% Privileged Time: All system-level activities, including disk access, are done in privileged mode (Kernel). If you find this counter on a dedicated SQL Server system is about 20 to 25 percent or more, then the system is probably doing a lot of I/O. The value at most should be about 5 to 10 percent.
-
Processor Queue Length: This counter is the number of threads in the processor queue. If the value is greater than 2 generally indicates processes congestion, because of multiple processors, you may need to take into account the number of schedulers dealing with the processor queue length.
-
Context Switches/Sec: This counter monitors the combined rate at which all processors on the computer are switched from one thread to another. A context switch occurs when a running thread voluntarily relinquishes the processor, is preempted by a higher-priority ready thread, or switches between user mode and privileged mode to use an executive or a subsystem service. The value should be between 300 to 1000, the value greater than 20000 per second can be caused by page faults due to memory starvation.
-
Batch Requests/Sec: This counter gives you a good indicator of just how much load is being placed on the system, which has direct correlation to how much load is being placed on the processor.
-
SQL Compilations/Sec: This counter shows both Batch compiles and statement recompiles as part of its aggregation. The value is extremely high when a server is first turned on but it will stabilize over time. Once stable, 100 or more compilations per second will certainly indicate problems in the processor.
-
SQL Recompilations/Sec: This counter is a measure of the recompiles of both batches and statements. A high number of recompiles will lead to processor stress.
Processor Bottleneck Resolution
Optimizing application workload is the most effective resolution most of the time, but because of the complexity and challenges involved in this process, it is usually considered as last resort.
-
Eliminating Excessive Compiles/Recompiles: A certain number of query compiles and recompiles is simply to be expected. A high number of compiles and a very low number of recompiles means that few queries are being reused within the system.
-
Using More or Faster Processors: The system’s processing power can be increased by increasing the power of individual processors or by adding more processors. When you have a high % Processor Time counter value and a low Processor Queue Length counter value, then it makes sense to increase the power of individual processors. In case that both counter values are high, then you should consider adding more processors.
-
Using a Large L2/L3 Cache: Modern processors have become so much faster than memory that they need at least two levels of memory cache to reduce latency. Not having enough L2/L3 cache can cause the processor to wait a longer period of time for the data/code to move from the main memory to the L2/L3 cache.
-
Running more Efficient Controllers/Drivers: There is a big difference in % Privileged Time consumption between different controllers and controller drivers on the market today. The techniques used by controller drivers to do I/O are quite different and consume different amounts of CPU time.
-
Not Running Unnecessary Software: Exterior applications that have nothing to do with maintaining the Windows Server or SQL Server are best placed on a different machine.
Network Bottleneck Analysis
In SQL Server, specially OLTP production environment, you find few performance issues that are because of problems with network. Most of the network issues you face in the OLTP environment are in fact hardware or driver limitation or issues with switches or routers. Most of these issues can be best diagnosed with the Network Monitor Tool. However, performance monitor also provides objects that collect data on network activity.
-
Bytes Total/Sec: This counter determines how the network interface card (NIC) or network adapter is performing. The counter value should be high to indicate a large number of successful transmissions. Compare this value with that reported by the Network Interface/Current Bandwidth counter, which reflects each adapter’s bandwidth. If the value is close to the capacity of the connection and if processor and memory usage are moderated, then the connection maybe a problem.
-
% Net Utilization: This counter represents the percentage of network bandwidth in use on a network segment. The threshold for this counter depends on the type of network. For Ethernet, 30% is recommended when the SQL Server is on the shared network hub. For dedicated full-duplex network, even near 100 percent usage is acceptable.
Network Bottleneck Resolution
-
Adding Network Adapters: You can add network adapters so that you have one network adapter per processor. If one of the processors is nearly always active and more than half of its time is spent servicing deferred procedure calls, then adding a network card is likely to improve system performance.
-
Moderating and Avoiding Interruptions: When adding or upgrading network adapters, choose adapters with drivers that support interrupt moderation and/or interrupt avoidance. Interrupt moderation allows a processor to process interrupts more efficiently by grouping several interrupts into a single hardware interrupt. Interrupt avoidance allows a processor to continue processing interrupts without new interrupts queued until all pending interrupts are completed.
Missing Indexes and Too Many Rows Requested
To analyze the overall performance of a SQL Server, besides examining hardware resource utilization, you should also examine some general aspects of SQL Server itself. To analyze the possibility of missing indexes causing table scans or large data set retrievals, you can use the following counters:
-
Free Space Scans/Sec: It represents a number of Insert Into a table with no physical ordering, such as Heap objects. Which needs extra processing.
-
Full Scans/Sec: It represents number of unrestricted full scan on base table or indexes, high Full Scans can be caused by either “Missing Indexes” or “Too many rows Requested”.
- To analyze the impact of database blocking on the performance of SQL Server, you can use the following counters:
-
Total Latch Wait Time (ms): It represents the number of milliseconds which SQL Server waits for internal structure’s integrity.
-
Lock Timeouts/Sec – Lock Wait Time (ms): Lock Timeouts/Sec value should be 0 and Lock Wait Time should be low as well, otherwise there are some deadlock within your database.
-
Number of Deadlocks/Sec: The expected value should be 0, otherwise needs to be investigated.
Non-Reusable Execution Plans
Since generating an execution plan for a stored procedure query requires CPU cycles, you can reduce the stress on the CPU by reusing the execution plan. To analyze the number of stored procedures that are recompiling, you can use the following counter:
-
SQL Re-Compilations/Sec: Recompilation of Stored Procedure has CPU overhead, the value of it should be close to 0, otherwise it needs to be investigated by SQL Server Profiler.
General Behaviors
SQL Server provides additional performance counters to track some general aspects of a SQL Server system, to analyze the performance, you can use the following counters:
-
Batch Requests/Sec: It indicates the SQL Server load, and it estimates number of users that SQL Server able to take without developing resource bottleneck.
-
User Connections: It indicates the number of users which are connecting to all SQL Server instances in the same machine.
 Applied to: SQL Server (2005-2022) , Azure SQL Database, Azure Synapse, Azure Fabric.
Applied to: SQL Server (2005-2022) , Azure SQL Database, Azure Synapse, Azure Fabric.

